Introduction
2025-07-01
Why learn Optimization?
Convex optimisation is an important field of applied mathematics. It involves finding the minimum of a given objective function subject to certain constraints. Optimisation has many applications in machine learning, computational physics, and finance. Examples include minimising risk for portfolio optimisation, minimising an error function to fit a machine learning model and minimising the energy of a system in computational physics.
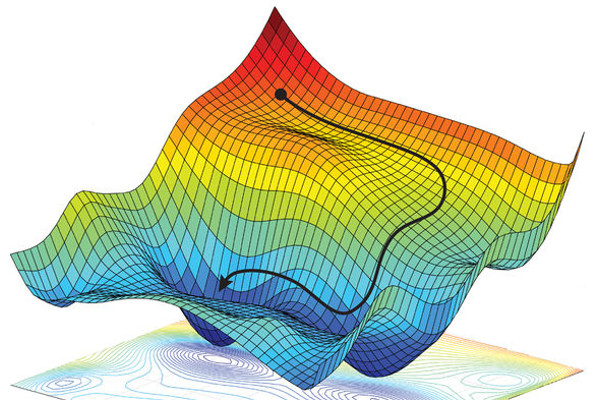
source: arXiv:1805.04829
Recommended Textbooks




1. Machine Learning
A common problem in machine learning is classification. You are given a set of points belonging to different classes and need to find a decision boundary to separate them. One possible solution is to fit the decision boundary so that the margin is maximised. This is the approach used by so-called Support Vector Machines (SVM).
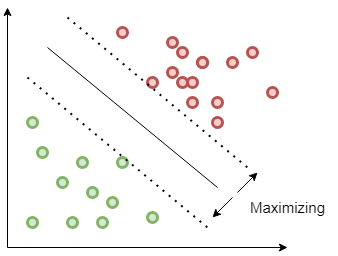
author: Sidharth GN, source: quarkml.com