Basics of Linear Algebra
2025-01-05
Hilbert spaces
Definition 3: Hilbert-space
A mapping \(\langle \cdot, \cdot \rangle : V \times V \to \mathbb{R}\) is called scalar product, if it has the following properties:
- symmetry: \(\langle \mathbf{x}, \mathbf{y} \rangle = \langle \mathbf{y}, \mathbf{x} \rangle\)
- positive definiteness: \(\langle \mathbf{x}, \mathbf{x} \rangle \gt 0\) for all \(\mathbf{x} \in V\)
- bilinear: \(\langle \alpha \mathbf{x} + \beta \mathbf{y}, \mathbf{z} \rangle = \alpha \langle \mathbf{x}, \mathbf{z} \rangle + \beta \langle \mathbf{y}, \mathbf{z} \rangle\)
A vector space equipped with a scalar product is called a pre-Hilbert space.
For a scalar product there holds the Cauchy-Schwarz inequality:
\[ \lvert \langle \mathbf{x}, \mathbf{y} \rangle \lvert \leq \lVert \mathbf{x} \rVert \, \lVert \mathbf{y} \rVert \]
Every pre-Hilbert space is a normed space with canonical norm \(\lVert \mathbf{x} \rVert := \sqrt{ \langle \mathbf{x}, \mathbf{x} \rangle}\). If the vector space is complete with respect to this norm, it is called a Hilbert space.
The dot product can be used to measure the angle between two vector in \(\mathbb{R}^n\):
\[ \lvert \langle \mathbf{x}, \mathbf{y} \rangle \rvert = \lVert \mathbf{x} \rVert \, \lVert \mathbf{y} \rVert \cos(\alpha) \]
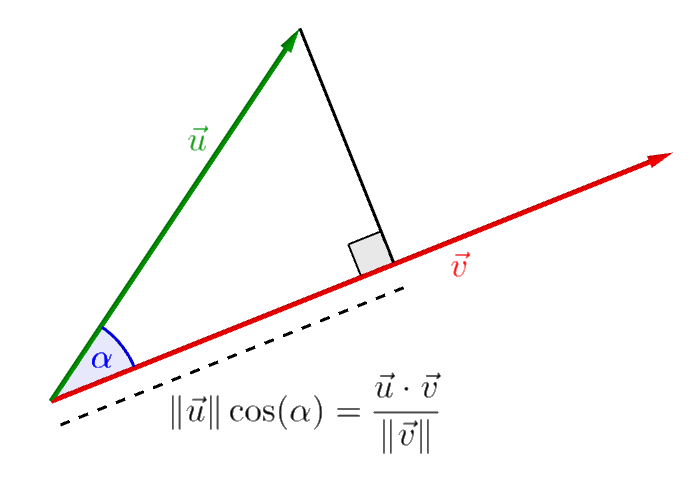
Two vectors are orthogonal, in symbols \(\mathbf{x} \perp \mathbf{y}\), if their dot product is 0.
The orthogonal projection \(P\mathbf{x}\) of a vector \(\mathbf{x}\) to a subspace \(M \subseteq V\) is determined by \[ \lVert \mathbf{x} - P \mathbf{x} \rVert = \min_{y \in M} \lVert \mathbf{x} - \mathbf{y} \rVert. \]
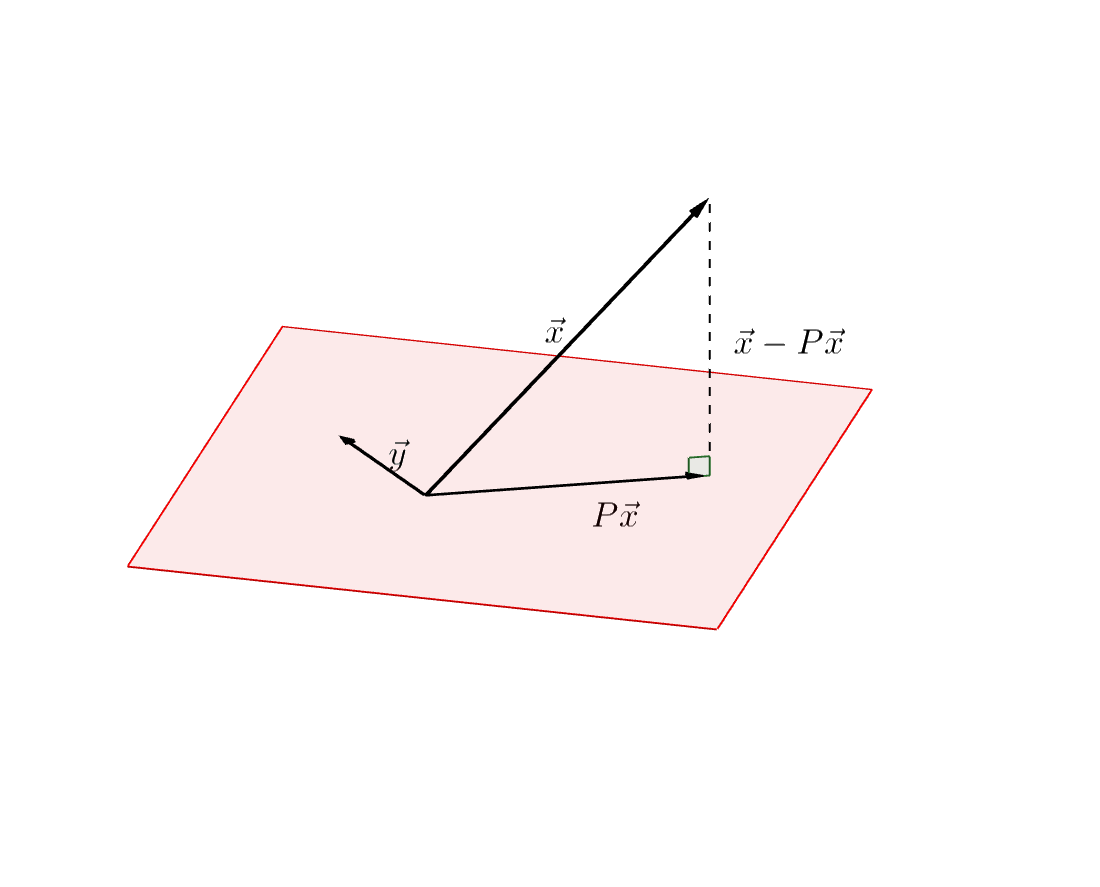
This is often called best approximation property and is equivalent to the relation \[ \langle \mathbf{x} - P \mathbf{x}, \mathbf{y} \rangle = 0 \quad \forall \mathbf{y} \in M. \]
Proof. See (Wendland 2018, Proposition 1.17 (p. 23)).
Note that \(A^\mathrm{T} A\) is symmetric for any matrix A. This means that by applying the previous theorem to \(A^\intercal A\) we can get a generalisation for non-symmetric matrices:
Theorem: The Singular Value Decomposition (SVD)
Let \(A \in \mathbb{K}^{n \times n}\) be arbitrary real or complex. Then, there exist unitary matrices \(V \in \mathbb{K}^{n \times n}\) and \(U \in \mathbb{K}^{m \times m}\) such that \[ A = U \Sigma V^\ast, \quad \Sigma = \mathrm{diag}(\sigma_1, \dotsc, \sigma_p) \in \mathbb{R}^{m \times n}, \quad p = \min(m, n) \] where \(\sigma_1 \geq \sigma_2 \geq \dotso \sigma_p \geq 0\).
Depending on whether \(m \leq n\) or \(m \geq n\) the matrix \(\Sigma\) has the form \[ \left( \begin{array}{ccc|c} \sigma_1 \\ &\ddots & & 0\\ & & \sigma_m \end{array} \right) \qquad \text{or} \quad \left( \begin{array}{ccc} \sigma_1 \\ &\ddots \\ & & \sigma_m \\ \hline & 0 \end{array} \right) \]
Proof. See Linear Algebra Done Right by Sheldon Axler, Springer (2025), Section 7.E.
From a visual point of view, the SVD can be thought of as a decomposition into a shear and two rotations.
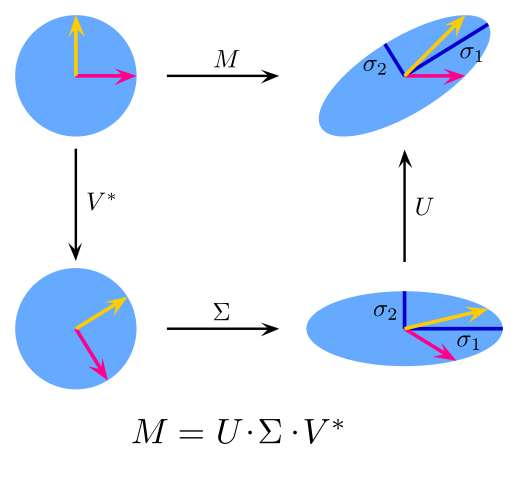
Author: Georg-Johann source: wikimedia.org license: CC BY-SA 3.0
{kind=link}
The Singular value decomposition has applications in machine learning, where it is often used for dimensionality reduction.